 Хочу написать об одной достаточно полезной, бесплатной утилите. Это LogParser.
Хочу написать об одной достаточно полезной, бесплатной утилите. Это LogParser.
Зачем она нужна? Она полезна если вам надо обработать большие текстовые файлы (например, логи) и быстро получить информацию. Кроме того она умеет доставать данные, полезные админам. IIS, EventLog и прочее.
Подчеркну, что если вы просто глянете о чём речь, то быстро поймёте как вы можете использовать это для себя.
Итак:
Теория:
Принцип прост – утилита позволяет использовать упрощенный sql для того, чтобы оперировать данными. Если звучит страшно – просто смотрите дальше :)
Утилита бесплатна, очень шустра и имеет множество возмжностей для расширения. По умолчанию она может работать с
Кроме того она умеет строить по этим данным графики.
Как происходит работа? Выбирается что именно мы будем смотреть, утилита преобразует это к табличному виду и позволяет оперировать данными при помощи языка SQL.
Есть некоторые примеры, которые вы можете использовать вообще без программирования. Например поиск самых больших файлов на вашем компьютере.
Например найти самые большие файлы на диске С выглядит вот так:
SELECT TOP 10 EXTRACT_PATH(Path), EXTRACT_FILENAME(Path), DIV(Size, 1048576) FROM C:\*.* ORDER BY DIV(Size, 1048576) DESC
Перевожу – выбрать 10 самых больших файлов, показать в виде путь к файлу, имя файла, размер в мегабайтах,
отсортировать по размеру в сторону уменьшения
Ну и так далее. Неплохой help позволит вам узнать какие там есть функции, а я покажу на примере как это выглядит…
Практика:
Качаем и устанавливаем сам LogParser
Далее, кому надо – устанавливаем графиеский интерфейс. Либо этот либо этот.
Первый лучше, но условно бесплатный. Т.е. для того, чтобы пользоваться всеми его возможностями надо его купить (около 8 евро). Второй бесплатен, но менее удобен.
И можно пользоваться… Есть готовые примеры, но я покажу как пользоваться этой штукой, если делать всё самому…
Например у нас есть файл D:\_temp\file1.txt :
name phone desc kolichestvo viktor +37060099999 opisanije viktora 1 lena +37060011111 opisanije leny 3 robert +37060022222 opisanije roberta 4
Например у нас есть файл D:\_temp\file2.txt :
name phone desc kolichestvo sergej +37060088888 opisanije sergeja 4 anna +37060077777 opisanije anny 1 dima +37060066666 opisanije dimy 7 sasha +37060055555 opisanije sashy 5
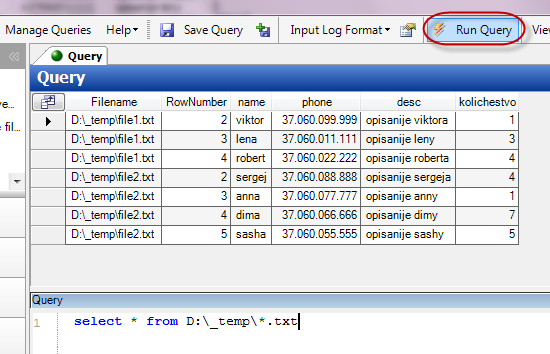
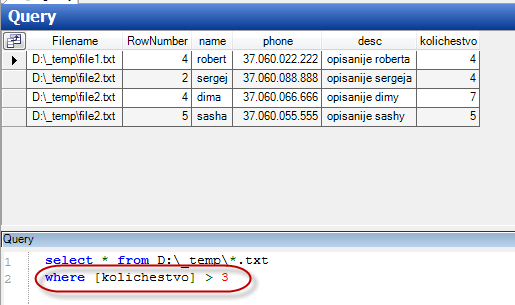
Тогда мы можем написать вот такой запрос:
select [name], [desc], [kolichestvo] from D:\_temp\*.txt where kolichestvo > 3
Создаём новый запрос:
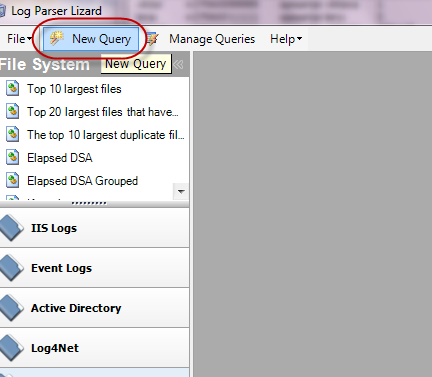
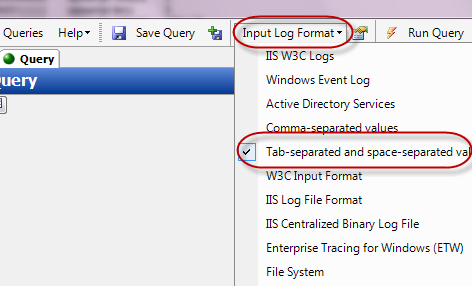
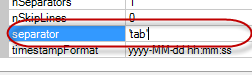
Указываем его формат (tab separated values – данные разделённый символом табуляции):
Запускаем запрос. Обратите внимание, что если указать не конкретный файл, а “маску” – обработаются оба файла…
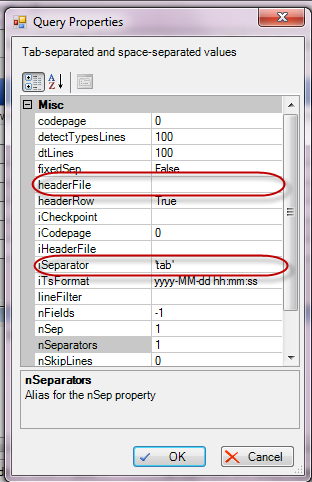
Можем уточнить параметры вот тут:
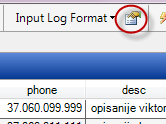
Например задатьфайл с заголовками столбцов или задать другой разделитель, отличный от табуляции:
Можем добавлять всякие условия:
Можно посмотреть график

Например вот так это выглядит:
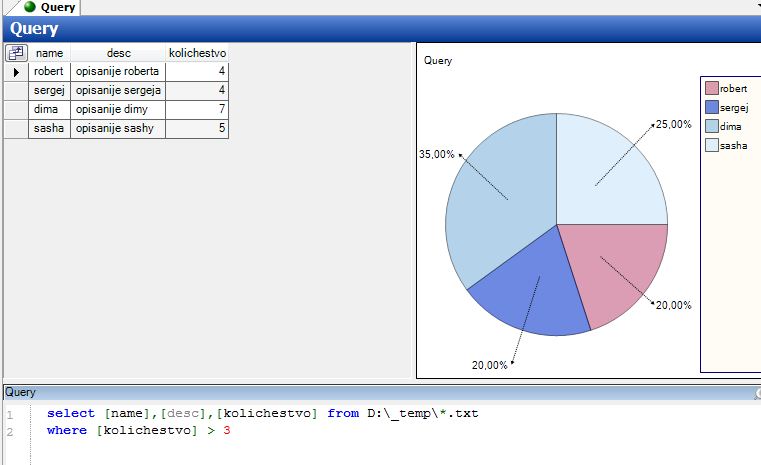
Всё вроде прозрачно :)
А как это превратить в командную строку?
"C:\Program Files\Log Parser 2.2\LogParser.exe" -i:TSV -iSeparator:space file:#chk.sql -o:TSV -fileMode:1
Если заголовки столбцов в отдельном файле – добавить строку -iHeaderFile:”templ.tsv”
например для работы с лога kannel (sms gate) sql выглядит, например, так:
select STRCAT(STRCAT( '\'', EXTRACT_TOKEN(EXTRACT_TOKEN( [To], 1, ':' ),0,']')),'\',') as phone_no using EXTRACT_TOKEN(EXTRACT_TOKEN( [REZSTAT], 1, ':' ),0,']') as Rez into C:\_REPO\ox2sms1\data\rez.tsv from C:\_REPO\ox2sms1\data\all.txt where ([SMS] = 'DLR') AND [Rez] <>'DELIVRD' order by phone_no
И всё это очень быстро (цитата с хабра):
Как видите, LogParser перемолотил почти полтора миллиона записей менее чем за 17 секунд с нетривиальными условиями на древнем Pentium D 2.8, что, на мой взгляд, далеко не такой плохой результат
Как-то так :) Если есть вопросы – с удовольствием отвечу…
Еще одна статья